Separation mechanisms
An overview of separation mechanisms to create boundaries in your system
Source-level boundaries
- Lowest-level boundaries
- Use mechanisms offered by the programming language (classes, interfaces, packages, modules, …)
- Communication through simple method calls
- Fast, don't have to worry about amount of communication passing boundary
- Easy to adjust and evolve the boundaries
- Might need additional enforcement if language mechanisms don't provide the necessary encapsulation
- What prevents internal code on one side of the boundary from directly calling internal code on the other side of the boundary?
- See below (Encapsulation) and Static analysis - Internal dependencies.
- Not visible at deployment time
- Does not mean they are not important! When set up correctly, they can still help to isolate different parts of the system from each other in order to facilitate independent development by multiple persons or teams
- Only kind of boundary in monolithic systems
Abstraction
Use your language's abstraction mechanisms to separate clients from implementations
Example: Strategy pattern

Encapsulation
Divide the code into modules where classes outside of a module can only see the classes that that module explicitly exposes
Examples in Java:
- Making classes package protected (limitation: Java does not have real notion of nested packages)
- The Java Platform Module System
If your language doesn't provide something like this, you may be able to set it up using automated tests that analyze dependencies, linting rules or some other kind of static analysis. See also Static analysis - Internal dependencies.
Data transfer objects
When passing data between components, the components can be more decoupled if the objects crossing the boundary are simple data transfer objects instead of actual specific classes that are being used on either side
Combining the above
Example of combining the above: use case boundary as specified by the Clean Architecture
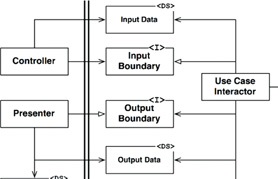
(image source )
- Abstraction, specifying interfaces for both client and provider
- Data transfer objects for input and output data
- Ideally, encapsulation is used to prevent clients from calling the implementation(s) of the input boundary interface directly
Also note that the Dependency Inversion Principle (from the SOLID principles) has been used to make sure all dependencies point from the component calling the use case to the use case component itself.
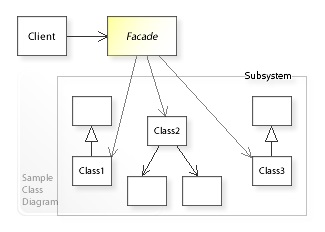
Simpler boundaries
An example of a simpler boundary is the Facade pattern . Here, you take a complex subsystem and put it behind a class that exposes a nice interface to that subsystem. This does not provide the same amount of separation as the use of abstractions and does not allow you to control the direction of dependencies, but it can help with managing complexity and potentially prepare for the creation of a full boundary.
Dynamically-linked deployable components
- Parts separated by the boundaries are separately developable and deployable components
- Example: DLL or JAR files
- Deployed independently, but they still run in the same address space
- Communication still through simple method calls
- Boundaries might need additional enforcement depending on how easy it is for code to access a component's internals
- When different components are developed independently from each other, you need some kind of versioning and release management system that allows developers depending on a component to decide if and when to upgrade to its next version
- Dependencies between components need to be managed carefully in order to prevent dependency cycles
- See Dependency Inversion Principle (from the SOLID principles)
See also Deployable components
Local processes
- Separate parts deployed as local processes
- Still live on the same machine, but they do not share the same address space (unless some memory sharing involved)
- Inter-process communication through shared memory, sockets or potentially some OS-specific mechanisms
- Context switching between processes (and potential marshalling and unmarshalling) means that the communication between processes has more overhead than just simple method calls. Where possible, unnecessary back-and-forth should be avoided.
- Boundaries easy to enforce (you can't just directly call some code running inside another process)
Services
- Strongest, highest-level boundary
- Different services are assumed to live on different machines and communicate only over the network
- Communication often happens over HTTP or some kind of message queue
- Communication between services is expensive from a performance point of view
- Communication between services can fail!
- Hard to adjust and evolve the boundaries
- Boundaries easy to enforce (you can't just directly call some code running inside a separate service)
- Service can be developed and operated by a separate team that takes ownership of the service, including its tech stack and data
- Freedom and flexibility: Ideally, changes to a service, except for its communication with other services, do not have any effect on other services
- Still some coupling! The fact that services communicate with each other means that services will still depend on each other to some extent
- Example: If your service needs customer data, there are scenarios where a change to the Customer service could impact you.
- These dependencies should be carefully managed
See also Microservices
Resources
- Clean Architecture (book by Robert C. Martin)
- Building Evolutionary Architectures (book by Neal Ford, Rebecca Parsons and Patrick Kua) (summary slides )